

AI content punished by the HCU update
AI content punished by the HCU update
Google's HCU update punished low-quality AI content after all. In this case study, I show why and how to detect it.

After the anti-climatic start of Google’s Helpful Content Update, the impact became visible towards the end of the 2-week rollout. Initial expectations that AI content would be hit hard weren’t met - until now. I found many examples of domains that were demoted due to AI content.
Since the September Core Update rolled out right when the HCU finished, I will provide a detailed analysis of domains next week. In this post, I present an example of a domain that was hit by HCU and punished for using low-quality AI content.
How easy it is to detect poor AI content
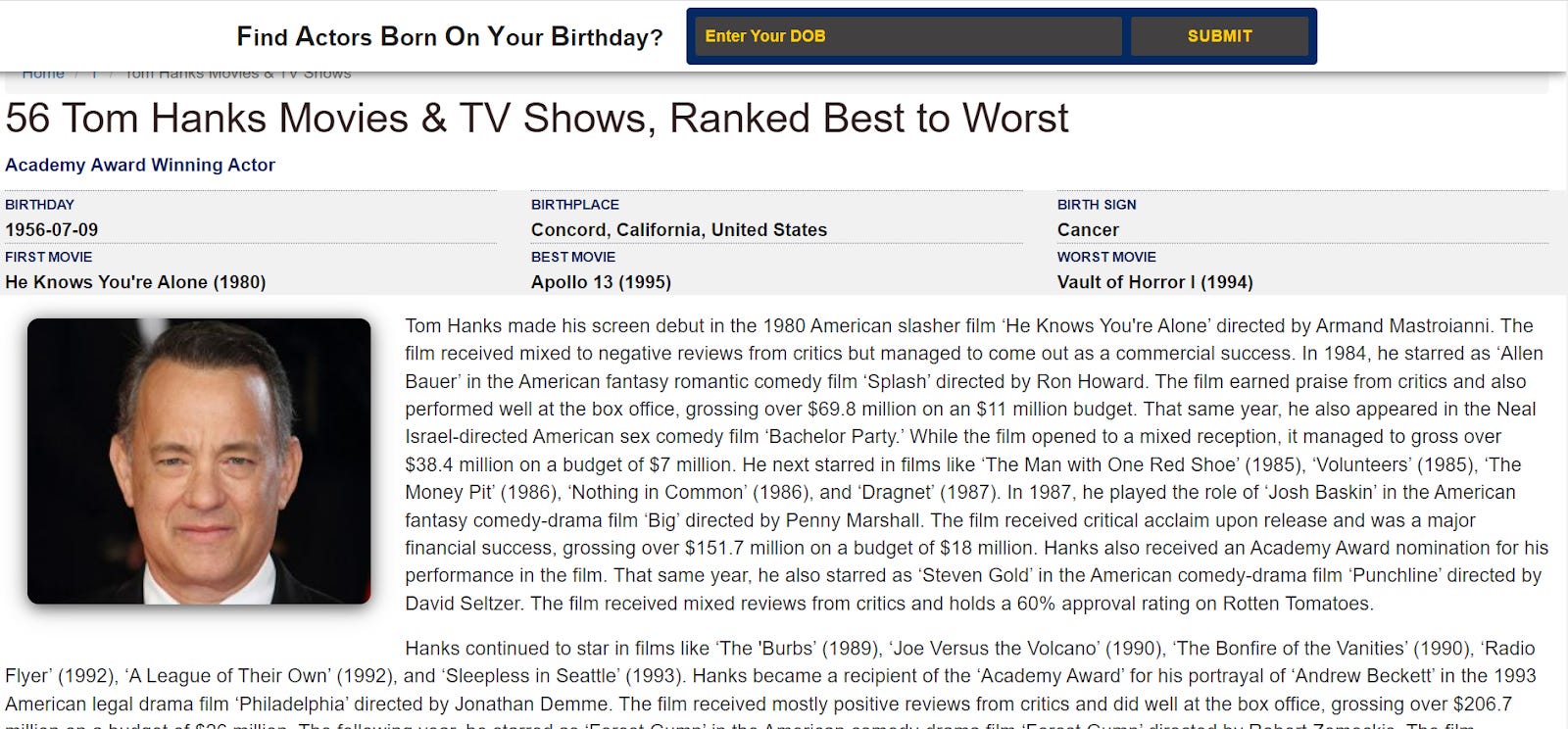
A strong example of poorly created AI content is throughtheclutter.com, a domain that provides celebrity profiles and movie histories. It’s the level of content quality that the HCU update punishes.
At its peak, throughtheclutter.com reached about 1M monthly users. On August 30th, ranks started to drop sharply. One week later, traffic tanked to almost 0.
Before even looking at traffic, you can tell something is going on with the domain by looking at the text formatting #walloftext.
The domain’s SEO visibility (screenshot below) shows the typical traffic development for sites that aggressively scale with AI content: a sudden increase, a plateau, and a sharp decrease.

To prove that the text was created by AI, I analyzed a sample with two different AI content detector tools.
The content sample is a text about Tom Hanks (see screenshot above): https://www.throughtheclutter.com/thomas-jeffrey-hanks-3063.php
I compared the outputs with a section from Tom Hank’s Wikipedia page: https://en.wikipedia.org/wiki/Tom_Hanks#1980s:_Early_work
Measuring visual footprint with GLTR
The first tool is GLTR, a tool from IBM Watson and Harvard NLP based on GPT-2. It measures the visual footprint of text to estimate how likely it is to be auto-generated (think: ai content).
You can see that the text from througtheclutter.com has a lot fewer red and purple words than the text from Wikipedia (screenshot below).
GLTR output for throughtheclutter.com
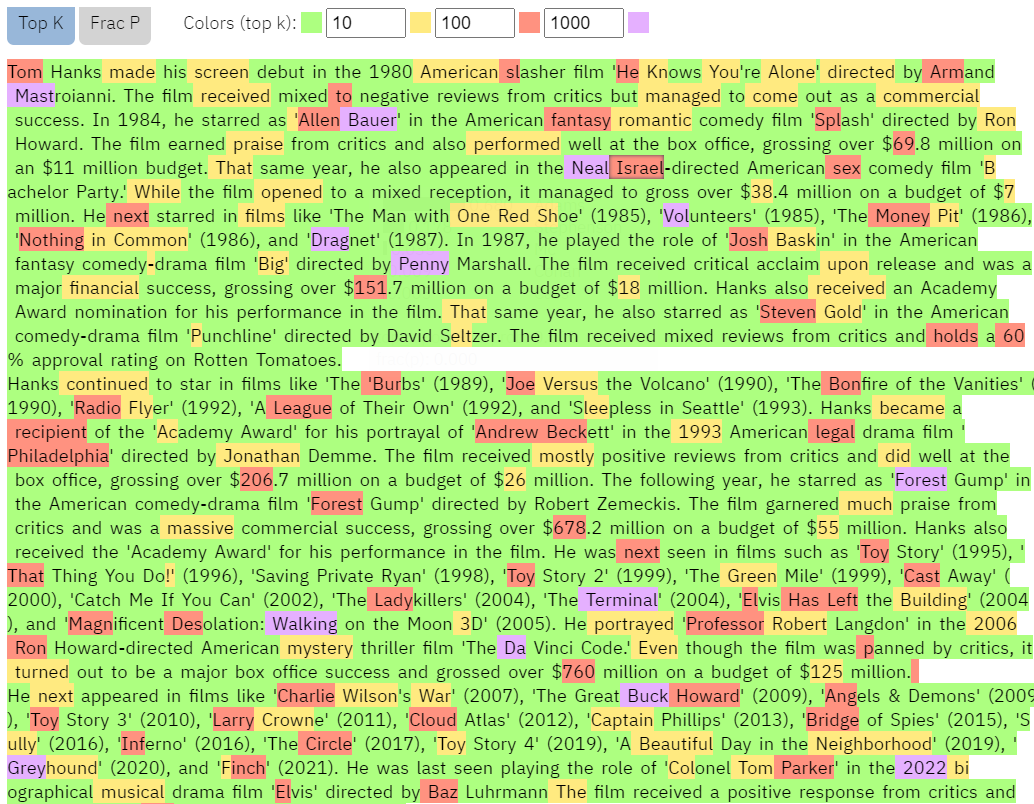
Red and purple words are “surprising” in GLTRs GPT-2 model, meaning they’re less likely to be predicted by an AI. As a result, the more green words a text has, the more likely it is to be written by an AI.
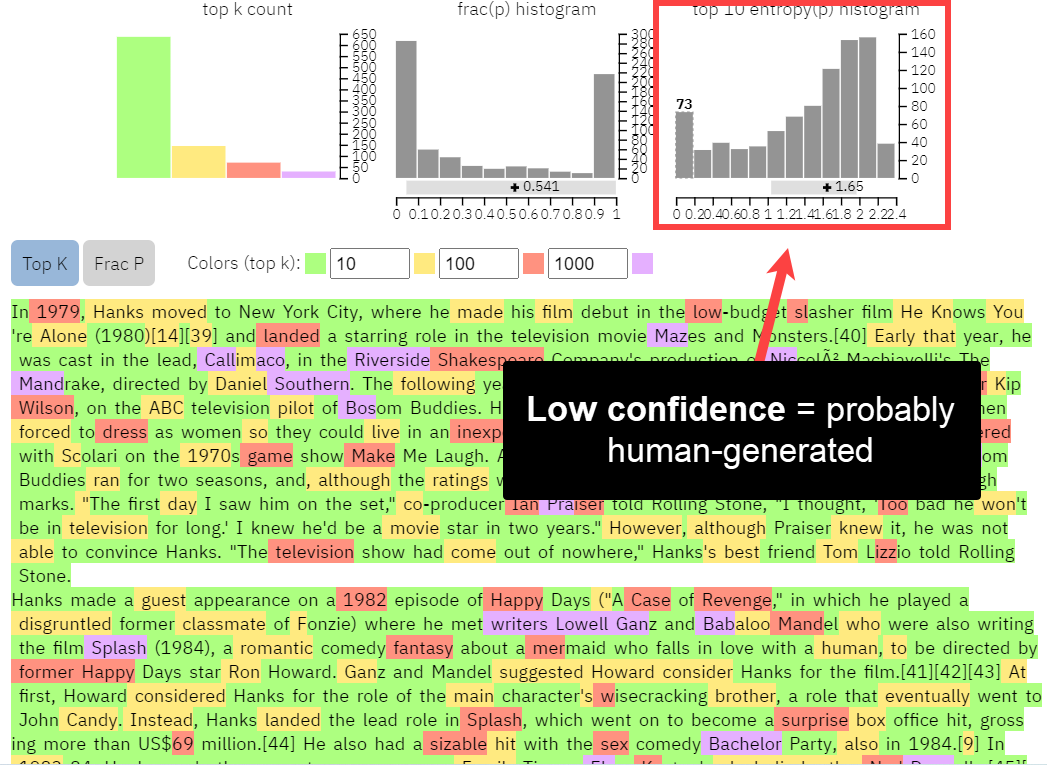
GLTR output for wikipedia.org

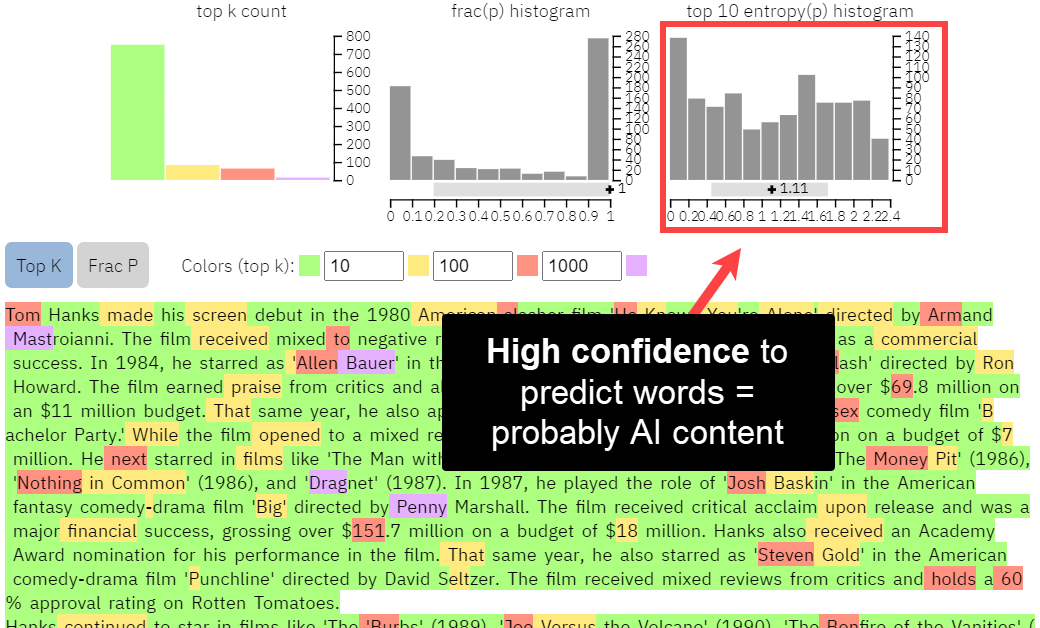
When we take this a step further and compare the histograms of the top 10 word predictions, we can see relatively high confidence across all modalities.
Wikipedia’s content, on the other hand, has low confidence in the lower bounds and higher confidence in the higher bounds, meaning the text is harder for the GPT-2 model to predict. The content is more likely to be created by humans.
The transformer technology in GPT, which stands for Generative Pre-trained Transformer, can predict text based on previous words. Google can detect AI content simply based on how “predictable” text is - especially compared to all the other content about the same topic in its corpus.
Huggingface Output Detector
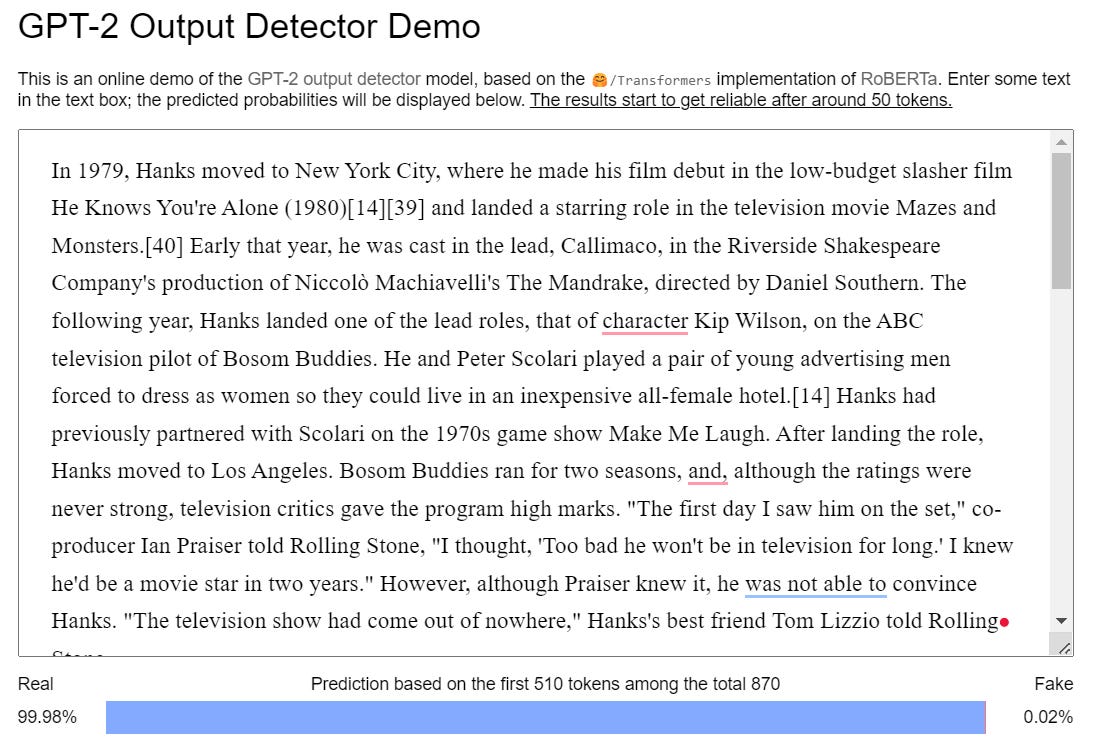
The second AI content detection tool, Huggingface’s GPT-2 Output Detector, is also built on GPT-2’s library but uses 1.5b parameters instead of GLTR’s 117M. The demo only analyzes the first 510 tokens, which is enough data for this case study.
The Output Detector finds a 19% likelihood that throughtheclutter.com’s text is fake.

That seems low at first, but it's actually quite high compared to the 0.02% probably for Wikipedia’s text.
Conclusion
Many companies that used AI to create content but ensured high-quality through editorial reviews and human polishing feared the HCU update would punish them. That turned out not to be the case. Instead, Google goes after the bottom of the barrel and scrapes super low-quality content off the SERPs.
The strategic move for companies is not to abide AI content altogether but to use tools like the public OpenAI GPT-2 library in their content creation workflows to decrease the predictability of text and increase the likelihood of driving organic traffic.
Even more important, integrators need to focus on user value and information gain in their content strategies - no matter who or what creates the content. The wall of text on throughtheclutter.com (ironic domain name) is not bad because it’s AI content but because the data formatting and presentation provide no user value. It’s hard to grasp cognitively and doesn’t contribute to the list of Tom Hanks movies, the target user intent of the page.